
Sora复刻版出现了——
Mora,还是多智能体那种。

△
Sora有的能力它基本都有,比如文本转视频、扩展视频、视频编辑、视频拼接、模拟数字世界等等。
广告 | Advertisement
在澳纽网做广告 | Advertise with us
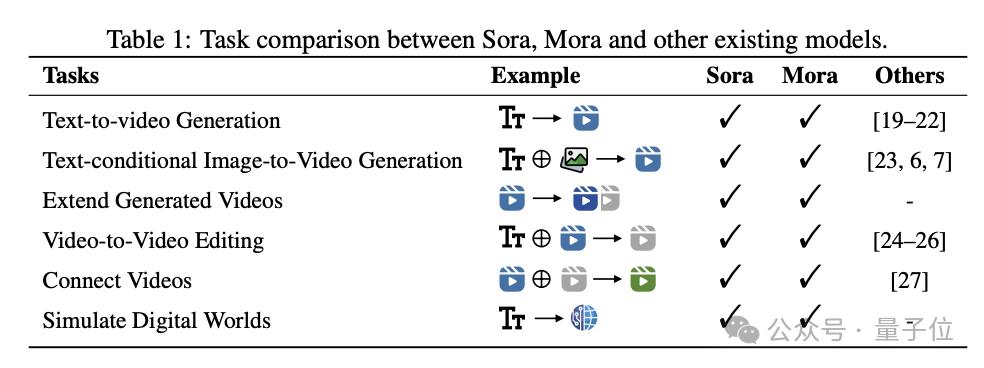
还支持生成1024*576分辨率的12秒视频。

这项研究来自理海大学微软研究院的华人团队。他们运用多个视觉agent,在多个任务中表现接近Sora。
既如此,且来看Mora究竟实力如何。
Mora复刻Sora
先来看效果。
首先是文本到视频的生成。
In the middle of a vast desert, a golden desert city appears on the horizon, its architecture a blend of ancient Egyptian and futuristic elements.The city is surrounded by a radiant energy barrier, while in the air, seve(在广袤的沙漠中,一座金色的沙漠城市出现在地平线上,其建筑融合了古埃及和未来元素。)

效果还不错,有点三体内味了。
再来看,基于文本提示的图像到视频生成。
不妨就拿Sora视频比较一下。

除此之外,还支持视频编辑,比如修改一下视频里的车、给车铺上一条彩虹之路。
这个效果嘛,就还有进步空间~
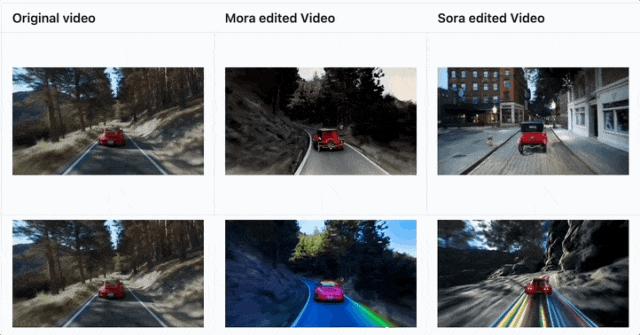
不过跟Sora同款的视频拼接,是可以Hold住的。

多智能体框架
研究团队提出了一个多智能体框架Mora。
他们认为解决不同视频生成任务,需要不同专业能力agent协作。为此,Mora框架中有5个基本角色组成:
Prompt选择和生成agent、文本到图像生成agent、图像到图像生成agent、图像到视频生成agent、视频到视频agent。
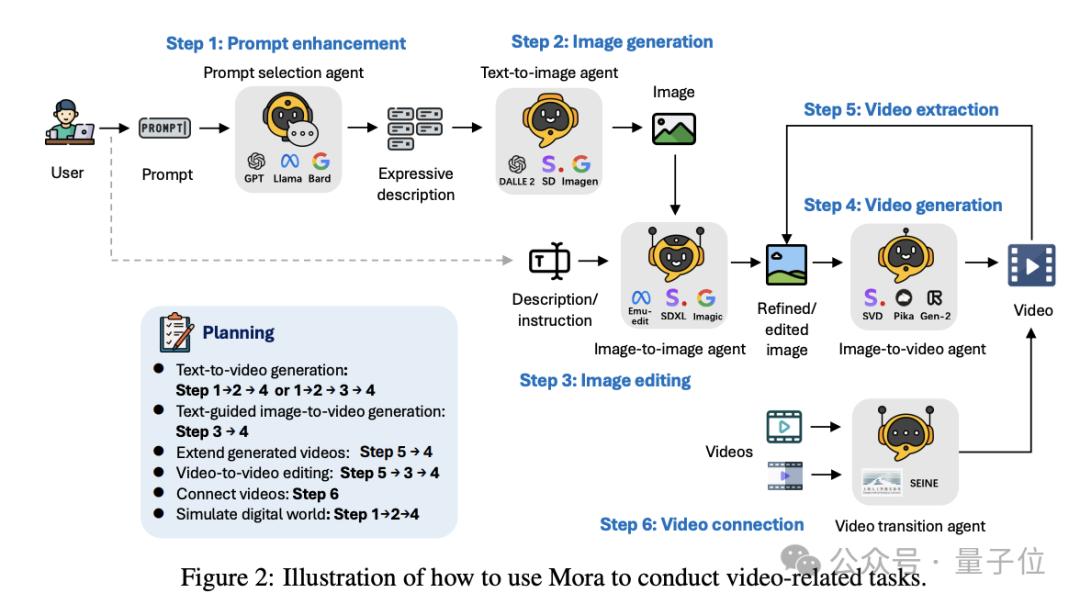
每个agent负责特定的输入和输出,通过设置agent的角色和操作技能,团队定义了各种任务基本工作流程。
广告 | Advertisement
在澳纽网做广告 | Advertise with us
根据任务不同,采用特定的agent组合。
目前他们主要设计了六个工作流:
文本到视频生成;文本条件图像到视频生成;扩展生成的视频;视频到视频编辑;连接视频以及模拟数字世界。
最终,在各个任务中,Mora的表现都接近Sora。
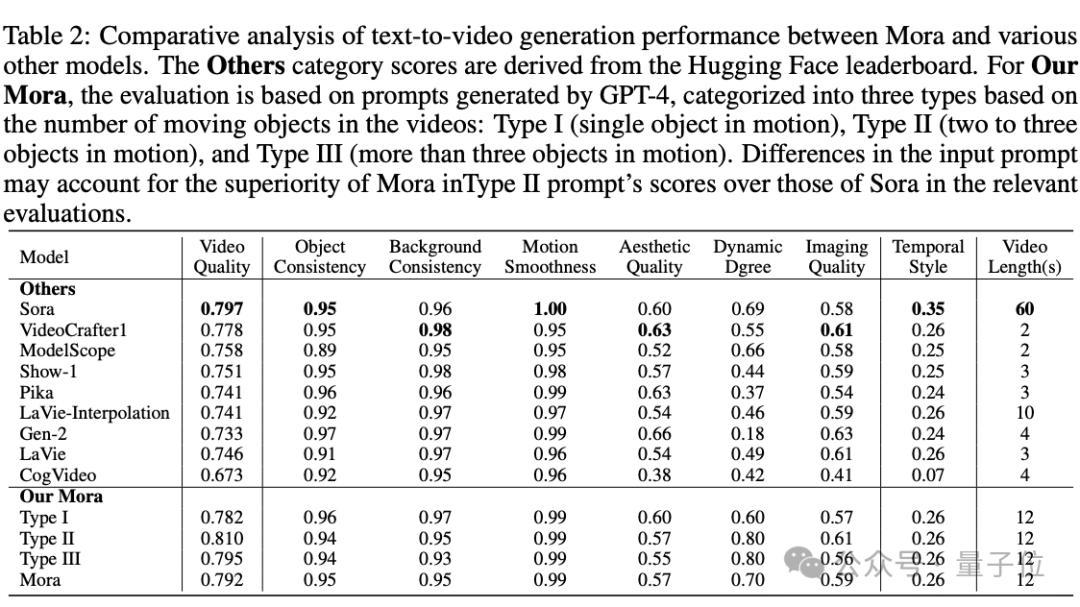



团队认为,Mora作为开源多agent框架,具有一定的灵活性和效率,还能无缝集成各种模型。
但与此同时,也有一定的进步空间。比如高质量视频数据集的需求、指令遵循能力的提升、人类视觉偏好对齐等。
理海微软团队
此次研究来自理海大学孙力超团队,此外还有微软研究院研究员参与。

前段时间,同样也是这个团队用37页论文逆向工程解剖Sora。
他们对模型背景、相关技术、应用、现存挑战以及文本到视频AI模型未来发展方向进行了全面分析。

感兴趣的朋友可戳下方链接:https://arxiv.org/abs/2403.13248https://github.com/lichao-sun/Mora
本文来自微信公众号“量子位”(ID:QbitAI),作者:白交
(即时多来源) 最新英语科技新闻 New Zealand English News
广告 | Advertisement
在澳纽网做广告 | Advertise with us
2,122 views

